Migrating Hosted Cluster among the same AWS Region
Preface and Considerations
The behaviour of this implementation is focused on the transparency for the user. Hypershift will not disrupt any customer workloads at anytime, also have in mind that the service workloads will be up and running during the migration process. Maybe at some point the Cluster API will be down but this will not affect the services running on the worker nodes.
In the storage side, It's mandatory to have under consideration that when we move a HostedControlPlane to another Management cluster we use some external services, which allows the migration to make it happen. We re-use the storage provisioned in AWS by the initial ControlPlane (PVs/PVCs) in the destination Management cluster.
Regarding the Workers nodes assigned to the cluster, during the migration they will still point to the same DNS entry, and we, under the hood, change the DNS Records to point to the new Management Cluster API, that way the node migration is transparent for the user.
NOTE: One considerations we should have is, both Hypershift deployments Source Management cluster and Destination Management cluster, had to have the
--external-dnsflags, in order to maintain the API server URL with the same entry. If that's not the case, the HostedCluster could not be migrated.
--external-dns-provider=aws \
--external-dns-credentials=<AWS Credentials location> \
--external-dns-domain-filter=<DNS Base Domain>
This way, the server URL will end in something like this: "https://api-sample-hosted.sample-hosted.aws.openshift.com"
The way that a Hosted Cluster migration follows, it's basically done in 3 phases:
- Backup
- Restoration
- Teardown
Let's setup the environment to start the migration with our first cluster.
Environment and Context
Our scenario involves 3 Clusters, 2 Management ones and 1 HostedCluster, which will be migrated. Depending on the situation we would like to migrate just the ControlPlane or the Controlplane + nodes.
These are the relevant data we need to know in order to migrate a cluster:
- Source MGMT Namespace: Source Management Namespace
- Source MGMT ClusterName: Source Management Cluster Name
- Source MGMT Kubeconfig: Source Management Kubeconfig
- Destination MGMT Kubeconfig: Destination Management Kubeconfig
- HC Kubeconfig: Hosted Cluster Kubeconfig
- SSH Key File: SSH Public Key
- Pull Secret: Pull Secret file to access to the Release Images
- AWS Credentials: AWS Credentials file
- AWS Region: AWS Region
- Base Domain: DNS Base Domain to use it as external DNS.
- S3 Bucket Name: This is the bucket in the same AWS Region where the ETCD backup will be uploaded
These are the Variables we will use in the scripts:
Sample Environment Variables
- Ensure all the file it's correct regarding you folder tree and put this env file in your filesystem, then execute `source env_file` from a terminalSSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub
BASE_PATH=${HOME}/hypershift
BASE_DOMAIN="aws.sample.com"
PULL_SECRET_FILE="${HOME}/pull_secret.json"
AWS_CREDS="${HOME}/.aws/credentials"
AWS_ZONE_ID="Z02718293M33QHDEQBROL"
CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica
HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift
HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift
HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"}
NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2}
# MGMT Context
MGMT_REGION=us-west-1
MGMT_CLUSTER_NAME="${USER}-dev"
MGMT_CLUSTER_NS=${USER}
MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}"
MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig"
# MGMT2 Context
MGMT2_CLUSTER_NAME="${USER}-dest"
MGMT2_CLUSTER_NS=${USER}
MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}"
MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig"
# Hosted Cluster Context
HC_CLUSTER_NS=clusters
HC_REGION=us-west-1
HC_CLUSTER_NAME="${USER}-hosted"
HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}"
HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig"
BACKUP_DIR=${HC_CLUSTER_DIR}/backup
BUCKET_NAME="${USER}-hosted-${MGMT_REGION}"
And this is how the Migration workflow will happen
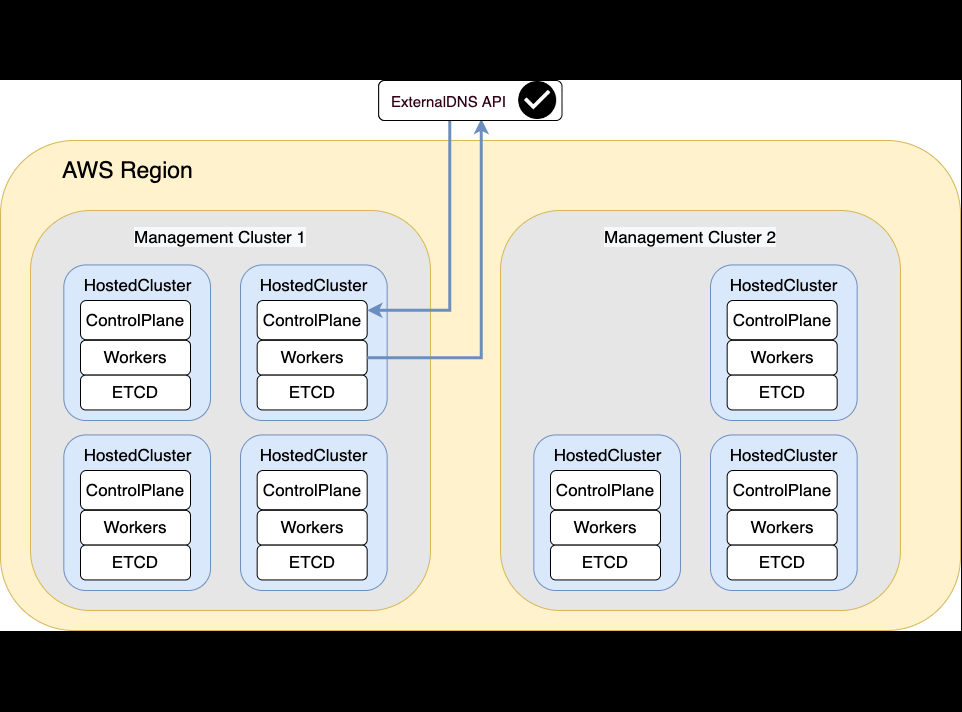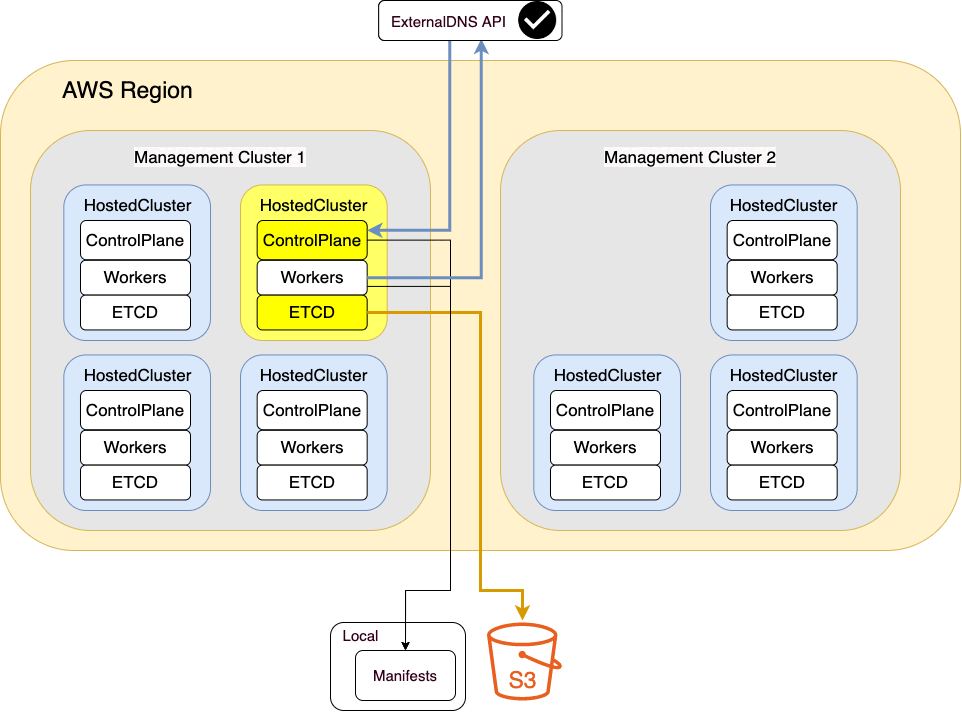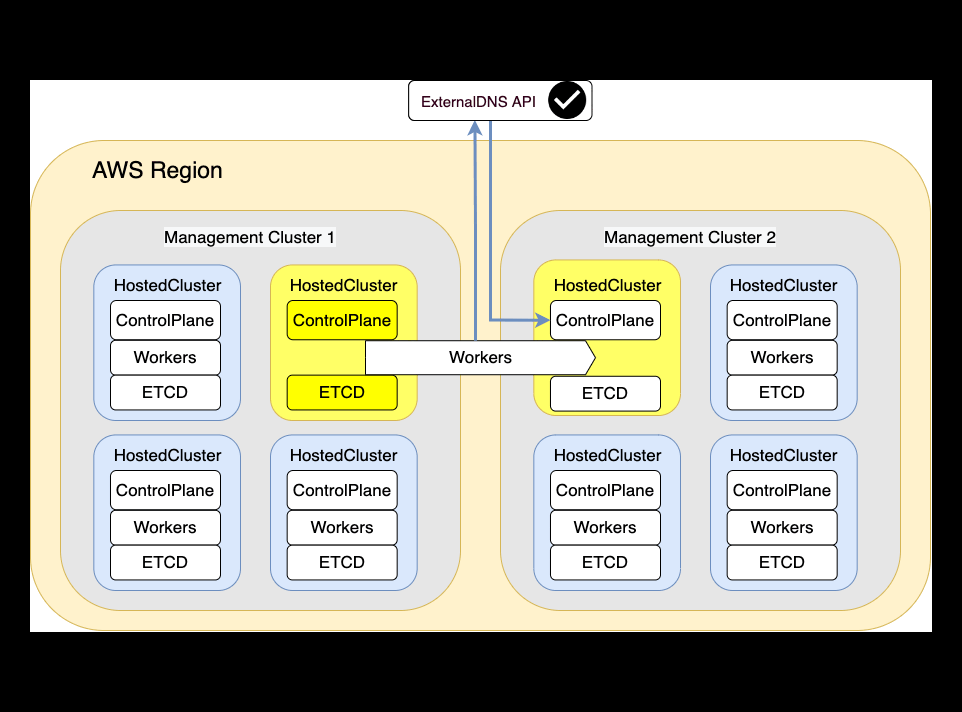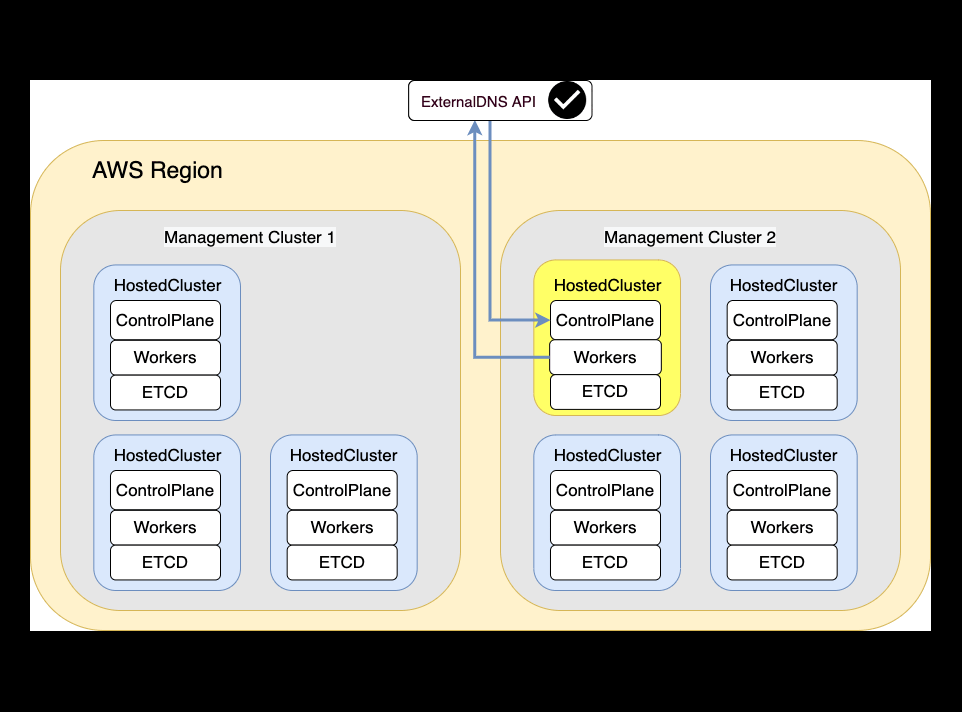
Backup
This section complains interaction among multiple components. We will need to backup all the relevant things to raise up this same cluster in our target management cluster.
To do that we will:
- Mark the Hosted Cluster with a ConfigMap which will declare the source Management Cluster it comes from (This is not mandatory but useful).
Config Map creation to set the Source Management Cluster
oc create configmap mgmt-parent-cluster -n default --from-literal=from=${MGMT_CLUSTER_NAME}
- Shutdown the reconciliation in the HostedCluster we want to migrate and also in the Nodepools.
ControlPlane Migration
PAUSED_UNTIL="true"
oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge
oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator
ControlPlane + NodePool Migration
PAUSED_UNTIL="true"
oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge
oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge
oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator
- Backup ETCD and Upload to S3 Bucket
The whole process of this step is documented here, even with that we will go through the process in a more programatically way.
To do this programatically it's a bit more complicated, but we will try to put all the necessary steps in a bash script
ETCD Backup and Upload to S3 procedure
- As an advice, we recommend to wrap it up in a function and call it from the main function.# ETCD Backup
ETCD_PODS="etcd-0"
if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then
ETCD_PODS="etcd-0 etcd-1 etcd-2"
fi
for POD in ${ETCD_PODS}; do
# Create an etcd snapshot
oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db
oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db
FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db"
CONTENT_TYPE="application/x-compressed-tar"
DATE_VALUE=`date -R`
SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}"
set +x
ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g")
SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g")
SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64)
set -x
# FIXME: this is pushing to the OIDC bucket
oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \
-H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \
-H "Date: ${DATE_VALUE}" \
-H "Content-Type: ${CONTENT_TYPE}" \
-H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \
https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db
done
-
Backup Kubernetes/Openshift objects
- Here we need to backup some Kubernetes objects to perform a successfully HC Migration, which includes:
- HostedCluster and NodePool Objects (from the HostedCluster Namespace)
- HostedCluster Secrets (from the HostedCluster Namespace)
- ControlPlane Secrets (from ControlPlane Namespace)
- MachineSets and Machines (from the HostedCluster Namespace)
- Here we need to backup some Kubernetes objects to perform a successfully HC Migration, which includes:
Openshift Objects backup
mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}
chmod 700 ${BACKUP_DIR}/namespaces/
# HostedCluster
echo "Backing Up HostedCluster Objects:"
oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml
echo "--> HostedCluster"
sed -i '' -e '/^status:$/,$d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml
# NodePool
oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml
echo "--> NodePool"
sed -i '' -e '/^status:$/,$ d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml
# Secrets in the HC Namespace
echo "--> HostedCluster Secrets:"
for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do
oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml
done
# Secrets in the HC Control Plane Namespace
echo "--> HostedCluster ControlPlane Secrets:"
for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do
oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml
done
# MachineSets
echo "--> HostedCluster MachineSets:"
for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do
ms_name=$(echo ${s} | cut -f 2 -d /)
oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml
done
# Machines
echo "--> HostedCluster Machine:"
for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do
m_name=$(echo ${s} | cut -f 2 -d /)
oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml
done
-
Cleanup the ControlPlane Routes
- This will allow the ExternalDNS Operator to delete the Route53 entries in AWS and they will not be recreated because of this HostedCluster it's paused.
HostedCluster ControlPlane Routes Cleanup
- Just to clean the routes you could execute this command, but you will need to wait until the Route53 are clean (this is why I will add an alternative to validate this step).oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all
function clean_routes() {
if [[ -z "${1}" ]];then
echo "Give me the NS where to clean the routes"
exit 1
fi
# Constants
if [[ -z "${2}" ]];then
echo "Give me the Route53 zone ID"
exit 1
fi
ZONE_ID=${2}
ROUTES=10
timeout=40
count=0
# This allows us to remove the ownership in the AWS for the API route
oc delete route -n ${1} --all
while [ ${ROUTES} -gt 1 ]
do
echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..."
echo "Try: (${count}/${timeout})"
sleep 10
if [[ $count -eq timeout ]];then
echo "Timeout waiting for cleaning the Route53 DNS records"
exit 1
fi
count=$((count+1))
ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${HC_CLUSTER_NAME})
done
}
# SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>"
clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
This was the last step on Backup stage, now we encourge you to validate all the OCP Objects and the S3 Bucket in order to ensure all is fine.
Restoration
This step it's basically catch all the objects which has been backuped up and restore them in the Destination Management Cluster.
NOTE: Ensure you have the destination's cluster's Kubeconfig placed as is set in
MGMT2_KUBECONFIG(if you follow the final script) orKUBECONFIGvariable if you are going step by step.export KUBECONFIG=${MGMT2_KUBECONFIG}orexport KUBECONFIG=<Kubeconfig FilePath>
- Ensure you don't have an old Namespace in the new MGMT Cluster with the same name as the cluster that are you migrating.
Delete the Namespace that will be used by the Migrated Cluster and the Control plane
# Just in case
export KUBECONFIG=${MGMT2_KUBECONFIG}
BACKUP_DIR=${HC_CLUSTER_DIR}/backup
# Namespace deletion in the destination Management cluster
oc delete ns ${HC_CLUSTER_NS} || true
oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || true
- ReCreate the deleted namespaces from fresh start
Namespace creation
# Namespace creation
oc new-project ${HC_CLUSTER_NS}
oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}
- Restore Secrets in the HC Namespace
Secrets Restoration in HostedCluster Namespace
oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*
- Restore Secrets in the HC ControlPlane Namespace
Restore OCP Objects related with the HC ControlPlane
oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-*
- (Optional) Restore Machines and MachineSets in the HC ControlPlane Namespace > NOTE: This step it's only relevant if you are migrating the Nodes and the NodePool to reuse the AWS Instances.
Restore OCP Machines and MachineSets related with the HC ControlPlane
oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*
oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-*
- Restore the ETCD Backup and HostedCluster
Bash script to restore ETCD and HostedCluster object
ETCD_PODS="etcd-0"
if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then
ETCD_PODS="etcd-0 etcd-1 etcd-2"
fi
HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml
HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml
HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml
cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE}
cat > ${HC_RESTORE_FILE} <<EOF
restoreSnapshotURL:
EOF
for POD in ${ETCD_PODS}; do
# Create a pre-signed URL for the etcd snapshot
ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db"
ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT})
# FIXME no CLI support for restoreSnapshotURL yet
cat >> ${HC_RESTORE_FILE} <<EOF
- "${ETCD_SNAPSHOT_URL}"
EOF
done
cat ${HC_RESTORE_FILE}
if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then
sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE}
sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE}
fi
HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true)
if [[ ${HC} == "" ]];then
echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace"
oc apply -f ${HC_NEW_FILE}
else
echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step"
fi
- (Optional) Restore the NodePool > NOTE: This step it's only relevant if you are migrating the Nodes and the NodePool to reuse the AWS Instances.
Restore the NodePool object
oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
This was our last step in the Restoration phase. If you are not migrating nodes, congratulations, you can pass to the next section Teardown.
(Optional) Now we will need to wait for some time until the Nodes gets fully migrated. We recommend to use this function
Ensure Nodes Migrated
timeout=40
count=0
NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0
while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ]
do
echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}"
echo "Try: (${count}/${timeout})"
sleep 30
if [[ $count -eq timeout ]];then
echo "Timeout waiting for Nodes in the destination MGMT Cluster"
exit 1
fi
count=$((count+1))
NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0
done
Teardown
In this section we will shutdown and delete the HostedCluster in the source Management Cluster.
NOTE: Ensure you have the source's cluster's Kubeconfig placed as is set in
MGMT_KUBECONFIG(if you follow the final script) orKUBECONFIGvariable if you are going step by step.export KUBECONFIG=${MGMT_KUBECONFIG}orexport KUBECONFIG=<Kubeconfig FilePath>
- Scale The Deployments and StatefulSets
ScaleDown Pod relevant objects in the HC ControlPlane Namespace
# Just in case
export KUBECONFIG=${MGMT_KUBECONFIG}
# Scale down deployments
oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all
oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all
sleep 15
- Delete the NodePool objects
Delete NodePools
NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}')
if [[ ! -z "${NODEPOOLS}" ]];then
oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'
oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS}
fi
- Delete the Machines and MachineSets
Delete Machines and MachineSets
# Machines
for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do
oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true
oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true
done
oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true
- Delete Cluster object
Delete the Cluster
# Cluster
C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)
oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'
oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all
- Delete the AWS Machines (Kubernetes Objects) > NOTE: Don't worry about the real AWS Machines, even if you delete this object, the CAPI controllers are down and will not affect the cloud instances
Delete AWS Machines OCP Objects
# AWS Machines
for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)
do
oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true
oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true
done
- Delete HostedControlPlane and Controlplane HC Namespace
Delete HostedControlPlane and ControlPlane HC Namespace objects
# Delete HCP and ControlPlane HC NS
oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'
oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all
oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true
- Delete the HostedCluster and HC Namespace
Delete the HostedCluster object
# Delete HC and HC Namespace
oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true
oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true
oc delete ns ${HC_CLUSTER_NS} || true
And that was it, following this whole process you could migrate an HostedCluster from one Management Cluster to other one in the same AWS Region.
To ensure all is working fine, you just need to validate that all the objects are in the right place:
# Validations
export KUBECONFIG=${MGMT2_KUBECONFIG}
oc get hc -n ${HC_CLUSTER_NS}
oc get np -n ${HC_CLUSTER_NS}
oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}
oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}
# Inside the HostedCluster
export KUBECONFIG=${HC_KUBECONFIG}
oc get clusterversion
oc get nodes
Migration Helper script
In order to ensure the that whole migration works fine, you could use this helper script that should work out of the box.
NOTE: The current implementation it's a temporary, until it gets included in the CLI.
HC Migration Script
In order to execute the script, just: - Fill the common variables - Execute a source into the env file `source env_file` - Execute the migration script without params. Now let's take a look to that script - Common Variables# Fill the Common variables to fit your environment, this is just a sample
SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub
BASE_PATH=${HOME}/hypershift
BASE_DOMAIN="aws.sample.com"
PULL_SECRET_FILE="${HOME}/pull_secret.json"
AWS_CREDS="${HOME}/.aws/credentials"
CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica
HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift
HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift
HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"}
NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2}
# MGMT Context
MGMT_REGION=us-west-1
MGMT_CLUSTER_NAME="${USER}-dev"
MGMT_CLUSTER_NS=${USER}
MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}"
MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig"
# MGMT2 Context
MGMT2_CLUSTER_NAME="${USER}-dest"
MGMT2_CLUSTER_NS=${USER}
MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}"
MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig"
# Hosted Cluster Context
HC_CLUSTER_NS=clusters
HC_REGION=us-west-1
HC_CLUSTER_NAME="${USER}-hosted"
HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}"
HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig"
BACKUP_DIR=${HC_CLUSTER_DIR}/backup
BUCKET_NAME="${USER}-hosted-${MGMT_REGION}"
#!/bin/bash
set -xeu
function change_reconciliation {
if [[ -z "${1}" ]];then
echo "Give me the status <start|stop>"
exit 1
fi
case ${1} in
"stop")
# Pause reconciliation of HC and NP and ETCD writers
PAUSED_UNTIL="true"
oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge
oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge
oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator
;;
"start")
# Restart reconciliation of HC and NP and ETCD writers
PAUSED_UNTIL="false"
oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge
oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge
oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=1 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator
;;
*)
echo "Status not implemented"
exit 1
;;
esac
}
function backup_etcd {
# ETCD Backup
ETCD_PODS="etcd-0"
if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then
ETCD_PODS="etcd-0 etcd-1 etcd-2"
fi
for POD in ${ETCD_PODS}; do
# Create an etcd snapshot
oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db
oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db
FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db"
CONTENT_TYPE="application/x-compressed-tar"
DATE_VALUE=`date -R`
SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}"
set +x
ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g")
SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g")
SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64)
set -x
# FIXME: this is pushing to the OIDC bucket
oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \
-H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \
-H "Date: ${DATE_VALUE}" \
-H "Content-Type: ${CONTENT_TYPE}" \
-H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \
https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db
done
}
function render_hc_objects {
# Backup resources
rm -fr ${BACKUP_DIR}
mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}
chmod 700 ${BACKUP_DIR}/namespaces/
# HostedCluster
echo "Backing Up HostedCluster Objects:"
oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml
echo "--> HostedCluster"
sed -i '' -e '/^status:$/,$d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml
# NodePool
oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml
echo "--> NodePool"
sed -i '' -e '/^status:$/,$ d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml
# Secrets in the HC Namespace
echo "--> HostedCluster Secrets:"
for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do
oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml
done
# Secrets in the HC Control Plane Namespace
echo "--> HostedCluster ControlPlane Secrets:"
for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do
oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml
done
# MachineSets
echo "--> HostedCluster MachineSets:"
for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do
ms_name=$(echo ${s} | cut -f 2 -d /)
oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml
done
# Machines
echo "--> HostedCluster Machine:"
for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do
m_name=$(echo ${s} | cut -f 2 -d /)
oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml
done
}
function restore_etcd {
ETCD_PODS="etcd-0"
if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then
ETCD_PODS="etcd-0 etcd-1 etcd-2"
fi
HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml
HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml
HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml
cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE}
cat > ${HC_RESTORE_FILE} <<EOF
restoreSnapshotURL:
EOF
for POD in ${ETCD_PODS}; do
# Create a pre-signed URL for the etcd snapshot
ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db"
ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT})
# FIXME no CLI support for restoreSnapshotURL yet
cat >> ${HC_RESTORE_FILE} <<EOF
- "${ETCD_SNAPSHOT_URL}"
EOF
done
cat ${HC_RESTORE_FILE}
if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then
sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE}
sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE}
fi
HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true)
if [[ ${HC} == "" ]];then
echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace"
oc apply -f ${HC_NEW_FILE}
else
echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step"
fi
}
function restore_object {
if [[ -z ${1} || ${1} == " " ]]; then
echo "I need an argument to deploy K8s objects"
exit 1
fi
if [[ -z ${2} || ${2} == " " ]]; then
echo "I need a Namespace to deploy the K8s objects"
exit 1
fi
if [[ ! -d ${BACKUP_DIR}/namespaces/${2} ]];then
echo "folder: ${BACKUP_DIR}/namespaces/${2} does not exists"
exit 1
fi
case ${1} in
"secret" | "machine" | "machineset")
# Cleaning the YAML files before apply them
for f in $(ls -1 ${BACKUP_DIR}/namespaces/${2}/${1}-*); do
yq 'del(.metadata.ownerReferences,.metadata.creationTimestamp,.metadata.resourceVersion,.metadata.uid,.status)' $f | oc apply -f -
done
;;
"hc" | "np")
# Cleaning the YAML files before apply them
for f in $(ls -1 ${BACKUP_DIR}/namespaces/${2}/${1}-*); do
yq 'del(.metadata.ownerReferences,.metadata.creationTimestamp,.metadata.resourceVersion,.metadata.uid,.status,.spec.pausedUntil)' $f | oc apply -f -
done
;;
*)
echo "K8s object not supported: ${1}"
exit 1
;;
esac
}
function clean_routes() {
if [[ -z "${1}" ]];then
echo "Give me the NS where to clean the routes"
exit 1
fi
# Constants
if [[ -z "${2}" ]];then
echo "Give me the Route53 zone ID"
exit 1
fi
ZONE_ID=${2}
ROUTES=10
timeout=40
count=0
# This allows us to remove the ownership in the AWS for the API route
oc delete route -n ${1} --all
while [ ${ROUTES} -gt 1 ]
do
echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..."
echo "Try: (${count}/${timeout})"
sleep 10
if [[ $count -eq timeout ]];then
echo "Timeout waiting for cleaning the Route53 DNS records"
exit 1
fi
count=$((count+1))
ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${HC_CLUSTER_NAME})
done
}
function backup_hc {
BACKUP_DIR=${HC_CLUSTER_DIR}/backup
# Create a ConfigMap on the guest so we can tell which management cluster it came from
export KUBECONFIG=${HC_KUBECONFIG}
oc create configmap ${USER}-dev-cluster -n default --from-literal=from=${MGMT_CLUSTER_NAME} || true
# Change kubeconfig to management cluster
export KUBECONFIG="${MGMT_KUBECONFIG}"
#oc annotate -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} machines --all "machine.cluster.x-k8s.io/exclude-node-draining="
NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}')
change_reconciliation "stop"
backup_etcd
render_hc_objects
clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "Z02718293M33QHDEQBROL"
}
function restore_hc {
# MGMT2 Context
MGMT2_REGION=us-west-1
MGMT2_CLUSTER_NAME="${USER}-dest"
MGMT2_CLUSTER_NS=${USER}
MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}"
MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig"
if [[ ! -f ${MGMT2_KUBECONFIG} ]]; then
echo "Destination Cluster Kubeconfig does not exists"
echo "Dir: ${MGMT2_KUBECONFIG}"
exit 1
fi
export KUBECONFIG=${MGMT2_KUBECONFIG}
BACKUP_DIR=${HC_CLUSTER_DIR}/backup
oc delete ns ${HC_CLUSTER_NS} || true
oc new-project ${HC_CLUSTER_NS} || oc project ${HC_CLUSTER_NS}
restore_object "secret" ${HC_CLUSTER_NS}
oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || oc project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}
restore_object "secret" ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}
restore_object "machine" ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}
restore_object "machineset" ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}
restore_etcd
restore_object "np" ${HC_CLUSTER_NS}
}
function teardown_old_hc {
timeout=40
count=0
NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0
while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ]
do
echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}"
echo "Try: (${count}/${timeout})"
sleep 30
if [[ $count -eq timeout ]];then
echo "Timeout waiting for Nodes in the destination MGMT Cluster"
exit 1
fi
count=$((count+1))
NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0
done
export KUBECONFIG=${MGMT_KUBECONFIG}
# Scale down deployments
oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all
oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all
sleep 15
# Delete Finalizers
NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}')
if [[ ! -z "${NODEPOOLS}" ]];then
oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'
oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS}
fi
# Machines
for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do
oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true
oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true
done
oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true
# Cluster
C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)
oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'
oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all
# AWS Machines
for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)
do
oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true
oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true
done
# HCP
oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'
oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all
oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true
oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true
oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} --wait=false || true
oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true
oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true
oc delete ns ${HC_CLUSTER_NS} || true
}
REPODIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )/.."
source $REPODIR/common/common.sh
backup_hc
echo "Backup Done!"
echo "Press enter to continue the migration"
read
restore_hc
echo "Restoration Done!"
teardown_old_hc
echo "Teardown Done"